Jenkins Pipeline Scalability in the Enterprise
| This is a guest post by Damien Coraboeuf, Jenkins project contributor and Continuous Delivery consultant. |
Implementing a CI/CD solution based on Jenkins has become very easy. Dealing with hundreds of jobs? Not so much. Having to scale to thousands of jobs? Now this is a real challenge.
This is the story of a journey to get out of the jungle of jobs…

Start of the journey
At the beginning of the journey there were several projects using roughly the same technologies. Those projects had several branches, for maintenance of releases, for new features.
In turn, each of those branches had to be carefully built, deployed on different platforms and versions, promoted so they could be tested for functionalities, performances and security, and then promoted again for actual delivery.
Additionally, we had to offer the test teams the means to deploy any version of their choice on any supported platform in order to carry out some manual tests.
This represented, for each branch, around 20 jobs. Multiply this by the number of branches and projects, and there you are: more than two years after the start of the story, we had more than 3500 jobs.
3500 jobs. Half a dozen people to manage them all…

Preparing the journey
How did we deal with this load?
We were lucky enough to have several assets:
-
time - we had time to design a solution before the scaling went really out of control
-
forecast - we knew that the scaling would occur and we were not taken by surprise
-
tooling - the Jenkins Job DSL was available, efficient and well documented
We also knew that, in order to scale, we’d have to provide a solution with the following characteristics:
-
self-service - we could not have a team of 6 people become a bottleneck for enabling CI/CD in projects
-
security - the solution had to be secure enough in order for it to be used by remote developers we never met and didn’t know
-
simplicity - enabling CI/CD had to be simple so that people having never heard of it could still use it
-
extensibility - no solution is a one-size-fits-all and must be flexible enough to allow for corner cases
| All the mechanisms described in this article are available through the Jenkins Seed plugin. |
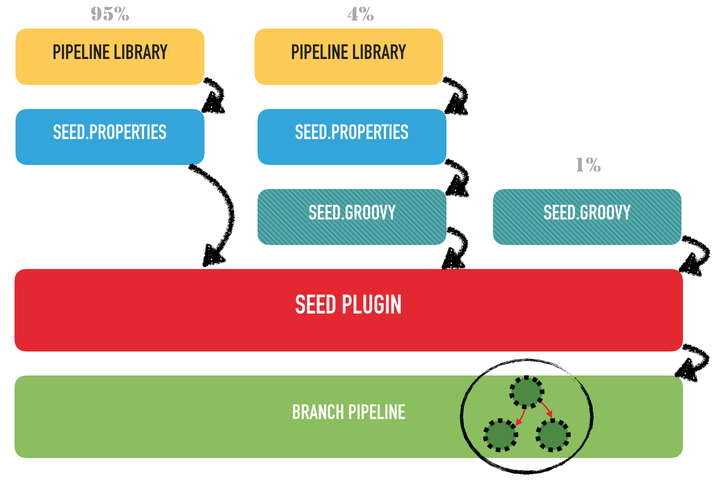
Creating pipelines using the Job DSL and embedding the scripts in the code was simple enough. But what about branching? We needed a mechanism to allow the creation of pipelines per branch, by downloading the associated DSL and to run it in a dedicated folder.
But then, all those projects, all those branches, they were mostly using the same pipelines, give or take a few configurable items. Going this way would have lead to a terrible duplication of code, transforming a job maintenance nightmare into a code maintenance nightmare.
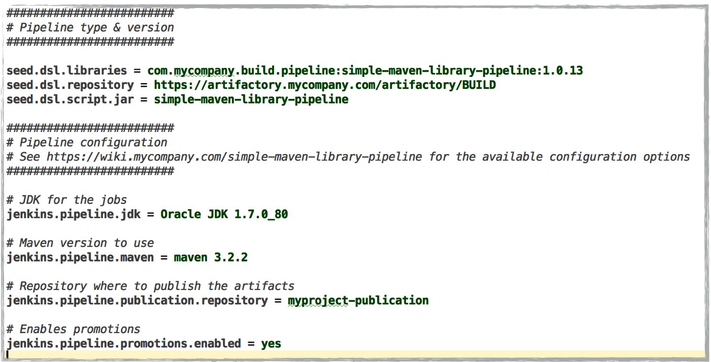
Pipeline as configuration
Our trick was to transform this vision of "pipeline as code" into a "pipeline as configuration":
-
by maintaining well documented and tested "pipeline libraries"
-
by asking projects to describe their pipeline not as code, but as property files which would:
-
define the name and version of the DSL pipeline library to use
-
use the rest of the property file to configure the pipeline library, using as many sensible default values as possible
-
Piloting the pipeline from the SCM
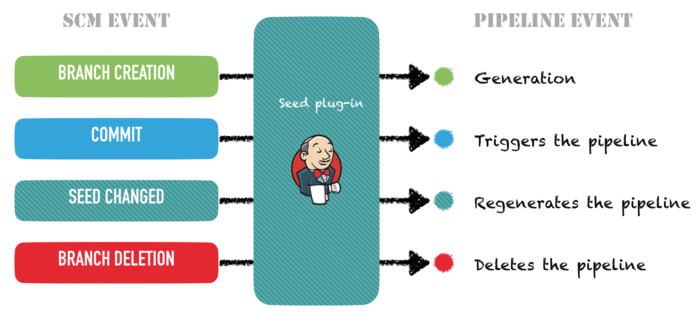
Once this was done, the only remaining trick was to automate the creation, update, start and deletion of the pipelines using SCM events. By enabling SCM hooks (in GitHub, BitBucket or even in Subversion), we could:
-
automatically create a pipeline for a new branch
-
regenerate a pipeline when the branch’s pipeline description was modified
-
start the pipeline on any other commit on the branch
-
remove the pipeline when the branch was deleted
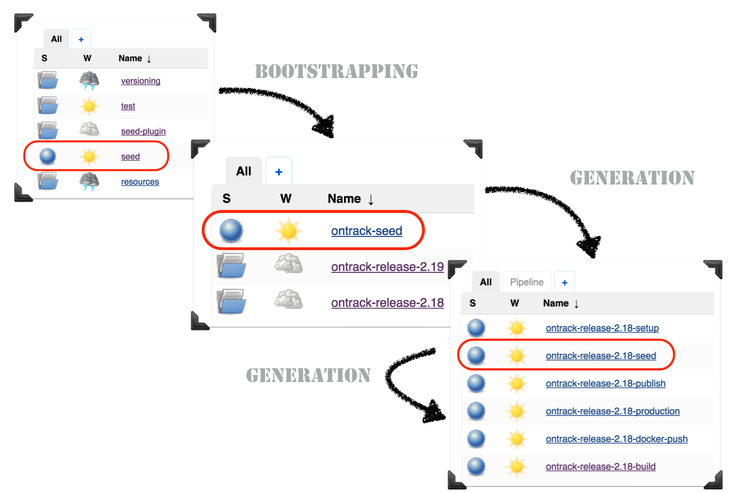
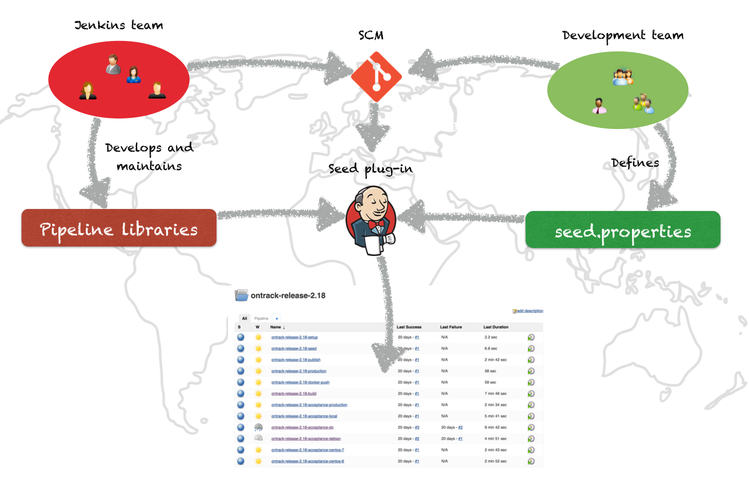
Once a project wants to go in our ecosystem, the Jenkins team "seeds" the project into Jenkins, by running a job and giving a few parameters.
It will create a folder for the project and grant proper authorisations, using Active Directory group names based on the project name.
The hook for the project must be registered into the SCM and you’re up and running.
Configuration and code
Mixing the use of strong pipeline libraries configured by properties and the direct use of the Jenkins Job DSL is still possible. The Seed plugin supports all kinds of combinations:
-
use of pipeline libraries only - this can even be enforced
-
use a DSL script which can in turn use some classes and methods defined in a pipeline library
-
use of a Job DSL script only
Usually, we tried to have a maximum reuse, through only pipeline libraries, for most of our projects, but in other circumstances, we were less strict and allowed some teams to develop their own pipeline script.
End of the journey
In the end, what did we achieve?
Self service ✔︎
-
Pipeline automation from SCM - no intervention from the Jenkins team but for the initial bootstrapping
-
Getting a project on board of this system can be done in a few minutes only
Security ✔︎
-
Project level authorisations
-
No code execution on the controller
Simplicity ✔︎
-
Property files
Extensibility ✔︎
-
Pipeline libraries
-
Direct job DSL still possible
Seed and Pipeline plugin
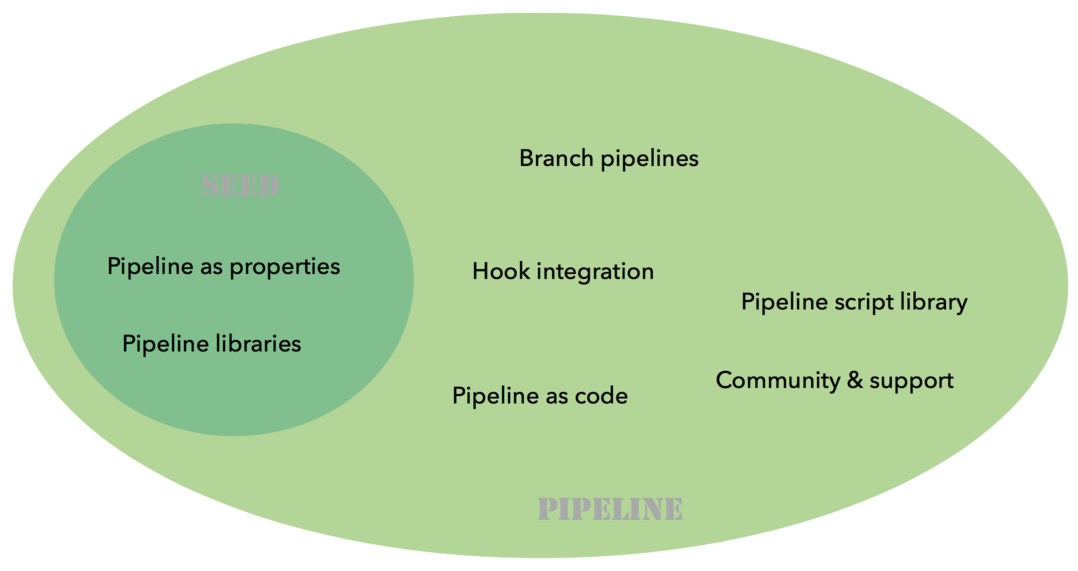
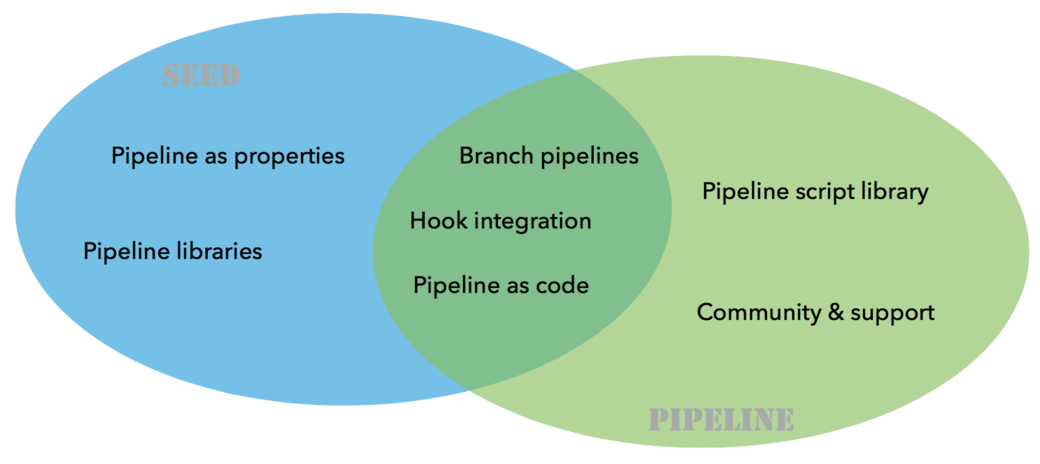
Now, what about the Pipeline plugin? Both this plugin and the Seed plugin have common functionalities:
What we have found in our journey is that having a "pipeline as configuration" was the easiest and most secure way to get a lot of projects on board, with developers not knowing Jenkins and even less the DSL.
The outcome of the two plugins is different:
-
one pipeline job for the Pipeline plugin
-
a list of orchestrated jobs for the Seed plugin
If time allows, it would be probably a good idea to find a way to integrate the functionalities of the Seed plugin into the pipeline framework, and to keep what makes the strength of the Seed plugin:
-
pipeline as configuration
-
reusable pipeline libraries, versioned and tested